By Bud Noren
Fulcrum Microsystems
The popularity of COTS-based cluster computing is rising rapidly thanks to the excellent cost/performance ratio of today’s Linux and commodity processor based systems. One way to measure this popularity is to look at the bi-annual listing of top supercomputers worldwide on TOP500.org. Nearly two-thirds of the most powerful computers on the planet have commodity Intel microprocessors at their heart. In fact 50% of these systems have between 500 and 1,000 processors with the Pentium 4 Xeon being the most common. Linux is particularly important in these applications because they require a multi-user, cost-effective operating system.
However, the most powerful cluster systems are not truly off-the-shelf – the one thing missing from the list of COTS components needed to build a cluster solution is the interconnect that links together all of the processors. The true COTS choice is Ethernet, which during its 22-year history has evolved into the de facto standard for networking worldwide and along the way built an ecosystem of complementary software and human expertise that rivals that of Windows or the x86 microprocessor.
Ethernet has seen success in the low-end of the cluster market. In fact, 50% of the cluster systems on the Top500.org listing use Gigabit Ethernet as the cluster interconnect. Why not more, given the broad ecosystem, low cost and wide availability of technology? The telling statistic is that these systems account only for 27% of the aggregate GFLOPS, whereas proprietary interconnects – which are used in only 4% of the systems – account for 23% of the GFLOPS.
Ethernet has had a latency issue when it comes to interconnect applications. Gigabit Ethernet switch chips, for example, had latencies that were an order of magnitude higher than the 300 nanoseconds required for high performance applications. Similarly, NICs had high latencies and burdened the host processor with a lot of IP/TCP processing.
But a new generation of 10-Gigabit Ethernet switch products is now available that boasts switching latencies of 200 ns – equal to or better than proprietary protocols – along with NICs that are similarly competitive to make 10-Gigabit Ethernet a true competitor in Linux cluster computers – and the only COTS technology available for the job.
Latency Considerations
Overall cluster latency is critical because a large cluster computing system can send many thousands of messages per second between processors and memory and a high latency means processors are starved for information while they wait for a memory’s reply.
Several factors impact latency in the data center, including the operating system and application overhead, the efficiency of the network adapter, and the switching infrastructure. Minimizing latency starts with a proper evaluation of the application to ensure it is optimized for a cluster environment. It may have too much interprocess communication to be successful with remote memory. Additionally, the overall architecture of the COTS cluster must be built in a balanced manner – meaning that the speed of the interconnect must be balanced against the speed of the processors such that there is a greater than 1:1 ratio of interconnect bandwidth to processing power (otherwise the processors are starved). The combination of bandwidth and latency restrictions significantly constrains performance as more processors are added.
Finally, two components of interconnect latency must be considered: NIC latency and switch latency. The NIC composes the message into a packet, which then must be switched through the network, before being received by the destination NIC, converted back into a message and forwarded to the destination processor.
Tackling Ethernet Latency
In recent months, standards activities and technology developments have yielded a low-latency 10-Gigabit Ethernet interconnect solution. An emerging suite of technologies, including RDMA, iWARP, iSER, and hardware-based TCP offload, are focused on reducing latency in Ethernet endpoints. These efforts are aimed at reducing the TCP processing load that a NIC puts on a host processor as well as its own time needed for packetizing messages. Combined, these activities historically add about 30 microseconds per NIC to the latency of a packet transmission. Several vendors have announced advanced NICs using these new technologies that offer sub-5 ms of latency, on par with the latency of InfiniBand, one of the fastest of the specialty fabric technologies.
This leaves switch latency, which becomes a bigger issue as the cluster becomes larger and data must pass through more switching nodes. In a two-tier hierarchical network, for example, data must flow through at least three switches compounding the end-to-end packet latency.
FIGURE: Latency comparison
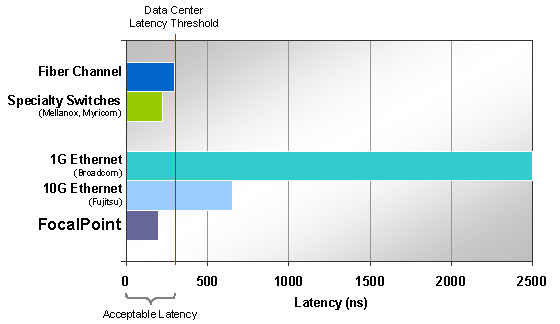
Several vendors have delivered switch chips that meet the requirements using standard Ethernet by optimizing their design for low latency. The pioneering switch device in this category is FocalPoint, a family of 10G Ethernet devices from Fulcrum Microsystems. FocalPoint features 24 10-Gigabit Ethernet ports with 200 ns of total cut-through latency, which is on par with all proprietary interconnect technologies. FocalPoint’s latency improvements come from proprietary circuit design techniques as well as highly efficient switch architecture.
The introduction of FocalPoint also changed the pricing structure for 10-Gigabit Ethernet, making it cost effective for COTS designs. In a report presented at the 2004 Usenix conference , Univ. of Iowa professors Brett M. Bode, Jason J. Hill, and Troy R. Benjegerdes, compared the cost and performance of a wide range of interconnect technologies. These ranged from $750/node for Gigabit Ethernet at the low end to $850/node to $4,000/node for proprietary interconnects. At the time of their research, the cost of a 10-Gigabit Ethernet solution was $10,000 per port. However, only one year later, FocalPoint was announced, which when paired with currently available NICs, results in a node cost in the range of $1,500. While not yet as low in cost as InfiniBand at less than $1,000/node, 10 Gigabit Ethernet is still in its infancy and given the very large potential volumes associated with Ethernet technologies in maturity, the node cost will continue its steep decline and soon surpass InfiniBand in hardware cost effectiveness. When operational and maintenance expenses are considered, the ubiquity and familiarity of Ethernet in the IT community will ensure that the total cost of a 10 Gigabit Ethernet solution will be considerably lower than all competing technologies
Scalability
Second-generation chips match the low latency with a high port density that give 10-Gigabit Ethernet the flexibility to build fat tree networks – one of the most popular interconnect architectures for high-performance clusters.
Fat tree networks, built on the work of Charles Leiserson of MIT, are growing increasingly popular with cluster computing designers because they can be scaled efficiently to support thousands of processors. This type of network is hierarchical with independent processors connected by tiers of interconnected switches. The links between the tiers grow “fatter”, containing sufficient bandwidth as they go up the tree toward the spine to ensure non-blocking switching between all nodes. Such a system, for example a 2-tier fat tree, can scale to a certain size by simply adding more switches in parallel and can scale beyond that by adding another tier of switches.
The fat tree architecture has not yet been 100% COTS because it requires a low-latency interconnect to scale beyond a few nodes. With a few extensions to low latency, high-port density 10-Gigabit Ethernet switches, a 3,456-port three-tier fat tree network can be constructed with less than 1 ms of switch latency between any two nodes.
As mentioned, fat tree networks are built by clustering processors, which could potentially be blade computers, together hierarchically. At the lowest level, these computers are connected to switches. In the case of a blade computer or AdvancedTCA chassis the switches might be cards that provide switching for every card in the chassis, or a switch chip might be built into each card relying on a passive backplane to provide physical interconnectivity.
These line switches are then connected to the first tier of fabric switches, which are in turn connected to the next tier of fabric switches and so on up the tree until they reach the root switch, which completes the connections. At each tier, the network connections must have more bandwidth to accommodate the aggregated traffic. Equally important, though, is the ability of a fabric switch to recognize a local conversation and to switch it to the proper adjacent computer. This locality improves the latency of the overall system by both minimizing the hops for that data stream and reducing overall bandwidth.
Latency and port density are crucial for Ethernet to serve as the interconnect in a COTS fat tree network. But a few other considerations are important as well.
Ethernet has a multitude of bandwidth speeds as well as a well-proven algorithm for link aggregation, which can deliver the increasing bandwidth levels needed to move up the tree. Individual computers can be connected to first-tier fabric switches at Gigabit speeds, which can be connected to the next tier at 10-Gigabit speeds. Then multiple links are aggregated for 20+ Gigabit throughput at higher tree levels. Up to 12 10-Gigabit trunks can be aggregated at the root level for throughput of 120 Gbps.
To keep conversations local, symmetric hashing implemented in the fabric switches guarantees that a conversation will be routed to the same fabric switches in both directions.
Another benefit of a fat tree network design is link redundancy ensured by multiple connections between fabric switches and also a load sharing capability built into the link aggregation. The use of link aggregation means that Ethernet’s Spanning Tree protocol still functions normally, ensuring that the redundant links don’t create endless network loops.
The goal of COTS systems is to reduce costs without sacrificing performance, and today’s generation of 10-Gigabit Ethernet switch products completes the equation. Indeed, even without being competitive in latency, Gigabit Ethernet has staked out a place in the cluster interconnect market. But with today’s technology there is no reason why even the highest performing Linux cluster systems can’t benefit from the low cost, high-performance, wide ecosystem and broad-base of industry knowledge that Ethernet brings to the table.
About Bud Noren
Bud Noren is senior product manager at Fulcrum Microsystems, http://www.fulcrummicro.com , responsible for the company’s PivotPoint product line. He comes to Fulcrum with extensive business and technical experience, most recently serving as director of marketing for Agile Materials & Technologies, a radio frequency and microwave circuit start up. Before that, his experience included marketing and product development roles at Vitesse Semiconductor and Hewlett Packard/Agilent Technologies. He graduated from Boston College with a bachelor’s degree in physics and earned a master’s in electrical engineering from Purdue University.









